
今回は、Power AutomateでSharePoint上に格納された5000件以上の大量のデータを処理する方法をご紹介します。
Power Automateで複数のデータを取得・処理するには複数の項目の取得アクションを使用しますが、フィルタークエリで絞り込んだ後でも5000件以上になってしまう場合には全てのデータに対して処理することができません。

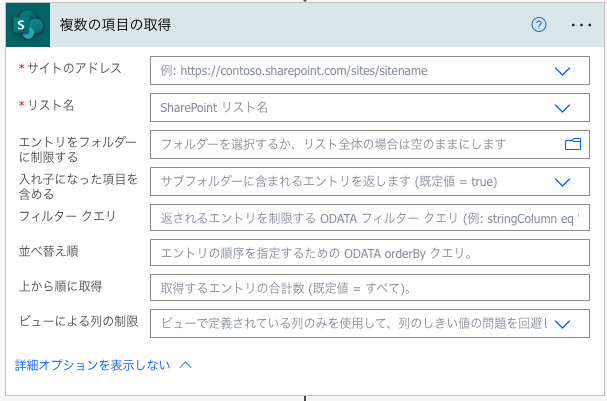
そのため、SharePointリストのデータを5000件ごとに区切って処理する方法を紹介します。
トリガーの設定
Power Automateフローを作成し、トリガーとして適切なアクションを設定します。
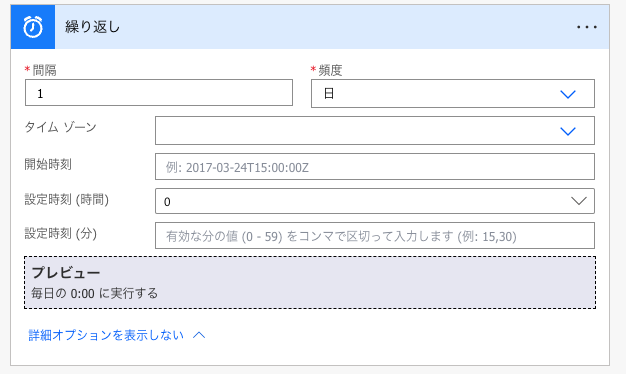
例えば、毎日夜中に大量のデータを処理するバッチ処理のようなフローでは、スケジュール→繰り返しを使用します。
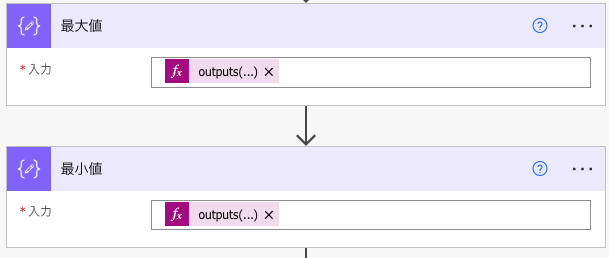
対象のリストにおけるIDの最小値と最大値を取得する
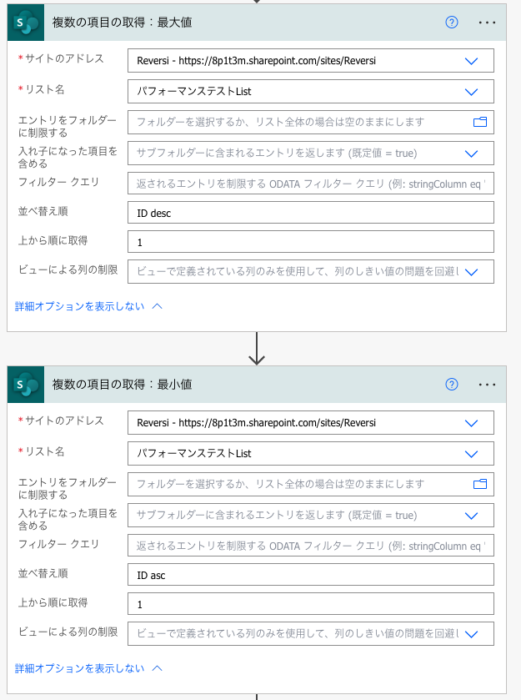
検索対象のリストにおけるIDの最大値と最小値を取得します。
並べ替え順を最大値側にはID desc、最小値側にはID ascを設定し、上から順に取得をどちらも1にすることで、最大値と最小値を取得できます。
後続のアクションで利用しやすいように、作成アクションで最大値(outputs('複数の項目の取得:最大値')?['body/value']?[0]?['ID'])と最小値(outputs('複数の項目の取得:最小値')?['body/value']?[0]?['ID'])を定数として設定しておきます。
ID最小値から最大値までを5000ごとに区切った配列を作成する
まずはID最小値〜ID最大値の差を5000で割ったものに1を足すことで、複数の項目の取得アクションを何回実行すればよいかを算出します。
複雑ですが、Power Automateの数式だと以下のようになり、この値をnとします。

add(div(sub(outputs('最大値'), outputs('最小値')), 5000), 1)次に、0からn-1までの配列を作成します。後続の処理を簡単にするために、0始まりの配列にしています。

range(0, outputs('n'))[0,…,n-1]配列に対して繰り返し処理を行う
Apply to eachを追加し、[0,…,n-1]配列を繰り返し対象に設定します。
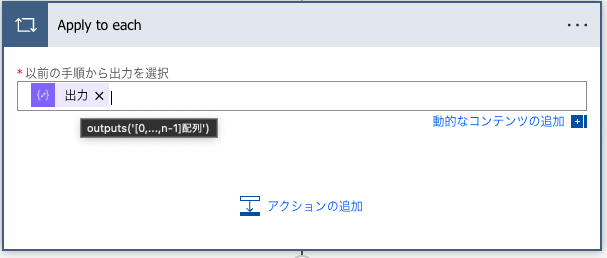
繰り返し中の最小値を設定します。
例えば、最小値が46で繰り返しが3回目(インデックスでは2)だと、繰り返し中の最小値は46 + 5000 × 2 = 10046です。

add(outputs('最小値'), mul(items('Apply_to_each'), 5000))この繰り返し中の最小値〜繰り返し中の最小値 + 5000の間でフィルタークエリを設定することで、適切な結果を取得し処理することができます。
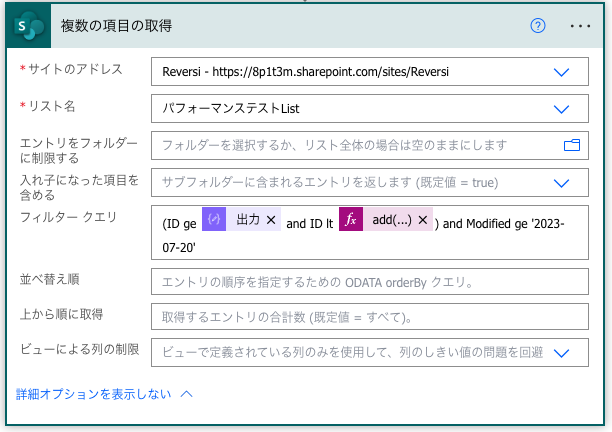
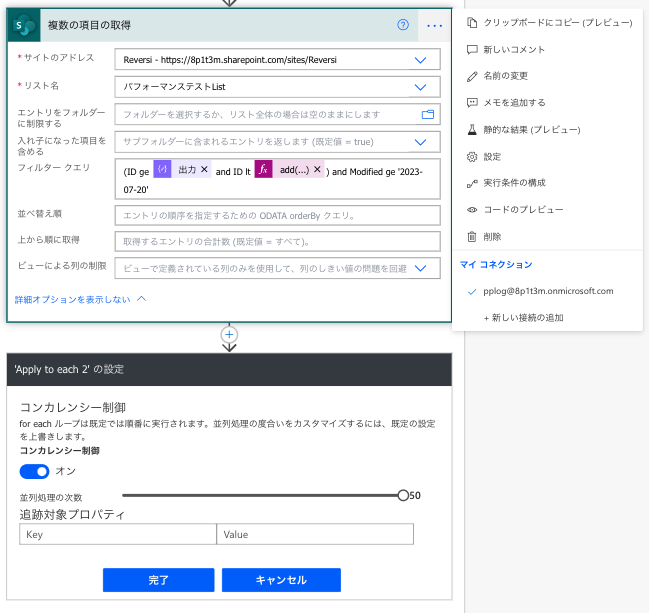
例えば、2023/7/20以降に変更されたデータのみ取得するには以下のように取得されたデータを繰り返し処理します。
独自の条件を設定する場合は、(ID ge~) and 以降の条件を変更して下さい。
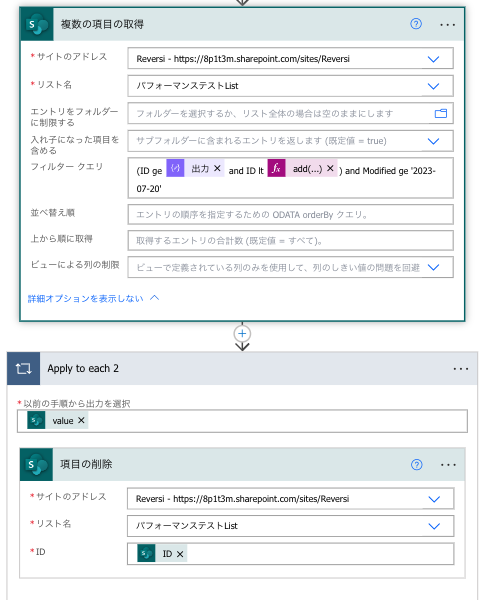
この例のようにただ削除するだけであれば、…→設定→コンカレンシー制御をオンにすることで、フローの高速化を実現できます。
この設定は並列処理を有効にするものであるため、順番に処理すべきようなフローの場合はオンにしないでください。
まとめ
複数の項目の取得アクションのフィルタークエリでフィルターをかけても、5000件以上になってしまう場合の対処法について紹介しました。
ただし、この方法は大量のAPI呼び出しを行う可能性があるので、パフォーマンスの低下につながる恐れがあることをご理解いただければ幸いです。
間違っている点や、もっといい方法があればぜひ教えて下さい。



コメント
はじめまして。Power AutomateでSharePointリストの5000件以上のデータを処理する方法 参考にさせていただきました。
気になった点をコメントさせていただきます。
・ID最小値から最大値までを5000ごとに区切った配列を作成する
add(div(sub(outputs(‘最大値’), outputs(‘最小値’)), 5000), 1)
こちらの式ですが、仮に最大値と最小値の差分が5000の倍数であった場合は、1を足すのは余分になってしまうかなと思いました。
また、0からn-1までの配列ですが
range(0, outputs(‘n’))
こちらの式だと0からnまでの配列になるのではないかと思いました。